SLM Experiment Log Book
This is a record of all pending and completed experiments run using the SLM Lab
The SLM Lab is built to make it easier to answer specific questions about deep reinforcement learning problems. These questions may be asked by students or researchers.
Students of deep reinforcement learning need to combine many different concepts and there are a large number of hyper-parameters to tune. This makes it tricker when compared to supervised learning to build intuition and understanding of the role of each of the different components. The Lab is intended to mitigate these challenges. It enables students to quickly test ideas and shed light on questions they might have through experimentation.
For researchers, the modular structure, baseline implementations of standard components, search, automated analytics framework, and fitness metric speeds up testing ideas, extending them, and comparing results.
Here are a few examples of questions that the Lab makes it easier to investigate.
- What is a good network architecture to solve the lunar landar environment using a DQN?
- Is the Actor-Critic family of algorithms more data efficient than REINFORCE?
- What is the impact of adding entropy to Actor-Critic policies?
- Is there a benefit to sharing parameters in Actor-Critic algorithms?
- Which environments benefit from using recurrent neural networks?
- What is the improvement that generalized advantage estimation adds over n-step forward returns?
The SLM-Lab functions like a science laboratory, and provides all of the components needed to setup, run, monitor, and analyze experiments. The main components are implementations of standard algorithms with flexible parameterizations, hyper-parameter search, agent fitness evaluation, and automated analytics. Most of these components have a lot in common with other libraries. The algorithm implementations with OpenAI baselines, hyper-parameter search with Ray, or analytics visualization with Tensorboard.
The SLM-lab emphasizes fast, reproduceable experimentation across a broad range of topics. On the whole this Lab provides broader but less deep functionality then any specific library, but it has the advantage of bringing all of the elements together in one place.
Focusing on experimentation naturally led to the question of agent evaluation. The Lab provides a multi-dimensional metric for evaluating agents that addresses not only the maximum score that agents reach (strength), but also their stability, speed, and consistency. This is not a feature that we have seen elsewhere and would welcome feedback as to whether it is a useful addition.
In addition to bringing the necessary components into one place, the prioritization of fast, and reproduceable experiments guided the design of the spec file. There is no need to store extensive command line arguments in a bash script or manually record what you have searched over. A spec file acts as both a record of the algorithm, default parameters, search parameters and the search range, and well as a set of instructions to the SLM-Lab about how to construct and run experiments - the number of trials and sessions, the relevant environments, etc. Everything is stored in one place and can be easily shared and re-run in a single line of code.
Answering questions with the SLM-Lab
To make this more concrete, let's walk through an example.
I am interested in understanding the effect of the value of the lambda parameter for an Actor-Critic algorithm with generalized advantage estimation in the CartPole environment provided by the OpenAI gym. This parameter controls the trade off between the bias and variance of the advantage estimation.
First I need to find a good set of parameters for all of the other components of the algorithm, otherwise the algorithm might end up stuck performing poorly for reasons not to do with the lambda parameter.
To find these parameters I write a spec to set up an experiment which will run a coarse search over a number of parameters. See "actor_critic_coarse_search" here for an example. It is also reproduced below.
"actor_critic_cartpole_coarse_search": {
"agent": [{
"name": "ActorCritic",
"algorithm": {
"name": "ActorCritic",
"action_policy": "default",
"gamma": 0.99, # discount rate per time step
"num_epis_to_collect": 1, # how many episodes of data to collect before training (when using episodic training)
"add_entropy": false, # whether to add entropy to the policy gradient loss
"entropy_weight": 0.01,
"continuous_action_clip": 2.0, # value to clamp actions to (+/-)
"lamda": 1.0, # GAE parameter controlling bias-variance trade off
"num_step_returns": 10, # number of forward step returns (when not using GAE)
"training_frequency": 32, # how frequency to train (when using batch training)
"training_iters_per_batch": 4, # how many critic updates to make per batch (when actor critic params are separate)
"use_GAE": true, # whether to use Generalized Advantage Estimation
"policy_loss_weight": 1.0, # weight on the policy loss when actor critic params are shared
"val_loss_weight": 1.0 # weight on the value function loss when actor critic params are shared
},
"memory": {
"name": "OnPolicyReplay", # type of memory - this is episodic
},
"net": {
"type": "MLPseparate", # network type - this is an MLP with separate networks for the actor and critic
"hid_layers": [64], # network shape (hidden layers)
"hid_layers_activation": "relu",
"use_same_optim": true, # whether to use the same optimizer for the actor and critic
"optim_actor": {
"name": "Adam",
"lr": 0.01
},
"optim_critic": {
"name": "Adam",
"lr": 0.01
},
"clamp_grad": false, # whether to clamp the gradients before updating parameters
"clamp_grad_val": 25.0, # value to clamp gradients to
"decay_lr": true, # whether to decay the learning rate
"decay_lr_frequency": 600, # how frequently to decay the learning rate
"decay_lr_min_timestep": 1000 # minimum time step after which to decay the learning rate
}
}],
"env": [{
"name": "CartPole-v0",
"max_timestep": null,
"max_episode": 1000
}],
"body": {
"product": "outer",
"num": 1
},
"meta": {
"max_session": 4,
"max_trial": 100,
"train_mode": true
},
"search": {
"agent": [{
"algorithm": {
"gamma__uniform": [0.9, 0.9999],
"training_iters_per_batch__choice": [1, 2, 3, 4, 5, 6, 8, 10],
"add_entropy__choice": [true, false]
},
"net": {
"type__choice": ["MLPshared", "MLPseparate"],
"hid_layers__choice": [
[16],
[32],
[64]
],
"hid_layers_activation__choice": ["relu", "sigmoid"],
"optim_actor": {
"lr__uniform": [0.001, 0.2]
}
}
}]
}
},
This searches over
- gamma: the discount rate
- training_iters_per_batch: the number of iterations to train the critic per batch (separate parameters only)
- add_entropy: whether to add entropy to the policy loss
- type: the network structure - shared or separate parameters
- hid_layers: structure of the MLP
- hid_layers_actionation: activation function
- optim_actor: learning rate for the actor and critic (since net.use_same_optim = True)
Running this experiment is simple. After saving the spec in a file called ac_cartpole_search.json in slm_lab/spec, I update config/experiments.json so that it contains the following
{
"ac_cartpole_search.json" : {
"actor_critic_cartpole_coarse_search" : "search"
}
}
This sets up the experiment to run in search mode. If you want the Lab to run more than one experiment, just add them to config/experiments.json and the Lab with schedule and run them all.
Then I run the experiment with
yarn start
1 experiment with 100 trials is completed, with each trial being run 4 times (sessions) and the results averaged.
After this is finished, hopefully I will have a good baseline set of parameters to hold fixed as I vary lambda. The experiment graph is the best place to look first for an overview of the results. If not, I can repeat the process with different search ranges and parameters until I have found a good set. An example experiment graph is included below.
data: actor_critic_cartpole_coarse_search_2018_01_30
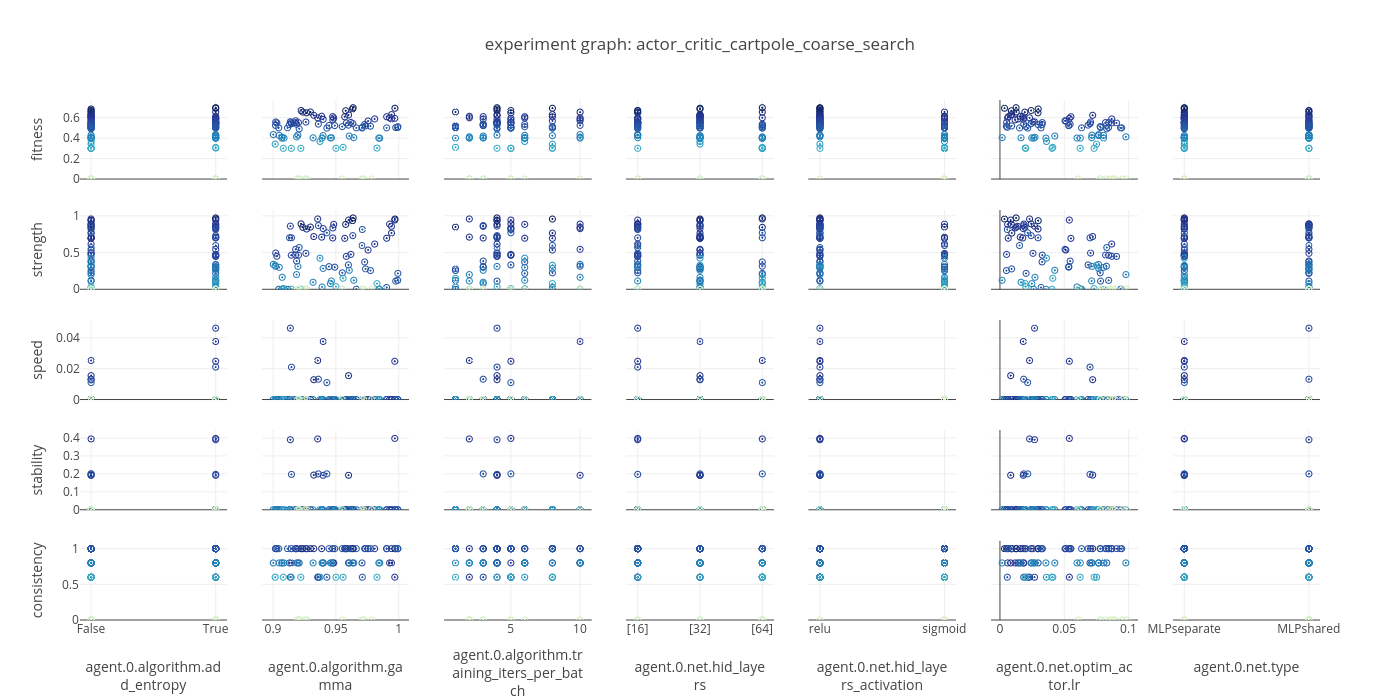
Next I update the parameters and set up a spec which will search over different lamda values.
"actor_critic_cartpole_lamda": {
"agent": [{
"name": "ActorCritic",
"algorithm": {
"name": "ActorCritic",
"action_policy": "default",
"gamma": 0.91,
"num_epis_to_collect": 1,
"add_entropy": true,
"entropy_weight": 0.01,
"continuous_action_clip": 2.0,
"lamda": 1.0,
"num_step_returns": 10,
"training_frequency": 32,
"training_iters_per_batch": 4,
"use_GAE": true,
"policy_loss_weight": 1.0,
"val_loss_weight": 1.0
},
"memory": {
"name": "OnPolicyReplay",
},
"net": {
"type": "MLPseparate",
"hid_layers": [16],
"hid_layers_activation": "relu",
"use_same_optim": false,
"optim_actor": {
"name": "Adam",
"lr": 0.02
},
"optim_critic": {
"name": "Adam",
"lr": 0.02
},
"clamp_grad": false,
"clamp_grad_val": 25.0,
"decay_lr": true,
"decay_lr_frequency": 1000,
"decay_lr_min_timestep": 2000
}
}],
"env": [{
"name": "CartPole-v0",
"max_timestep": null,
"max_episode": 500
}],
"body": {
"product": "outer",
"num": 1
},
"meta": {
"max_session": 5,
"max_trial": 75,
"train_mode": true
},
"search": {
"agent": [{
"algorithm": {
"lamda__uniform": [0.0, 1.0]
},
}]
}
},
I run it using the same process as before - saving spec file as ac_cartpole_lamda.json and updating config/experiments.json as follows, and run as before.
{
"ac_cartpole_lamda.json" : {
"actor_critic_cartpole_lamda" : "search"
}
}
This time 1 experiment with 75 trials are run, with each trial being run 5 times (5 sessions per trial) and the results averaged. When this is finished, I can look at the experiment graph to understand the sensitivity of the algorithm's performance to the lambda parameter in this environment. The components of the fitness metric allow me to asses the effect of lambda on the reward the agent obtains (strength), how fast it does it (speed), how stable and how consistent performance is.
The SLM-Lab log book
A science lab also has log book - a record of the experiments run and the results. This book documents the questions we are trying to answer using the Lab and as we continue to learn about Deep RL. It is a living document, and we will continue to upload our results, the instructions for reproducing the experiment in the lab. We hope that it will be useful for RL students and researchers.
Contributions
We are always interested to learn what people have discovered using the lab. If you have run an experiment with the Lab that you think is interesting, please get in touch.