Actor Critic Benchmark
Proposed by Konda and Tsitsiklis in 2003, Actor Critic is a method that uses an actor and a critic. The actor outputs parameters to sample the actions; the critic calculates the value for the policy loss.
Plain AC uses TD error for loss, in contrast with an advantage function for A2C.
TODO clear below; link original paper
Name: Actor Critic Benchmark
Date completed: 2018_02_04_013652, ongoing
Description: Standard Benchmark on Actor Critic
Hypotheses: N/A
Prerequisites: N/A
Algorithms: Actor Critic episodic training
Environments: CartPole-v0, Acrobot-v1
Specs: ("actor_critic.json", "actor_critic_benchmark")
Running instructions:
{
"actor_critic.json": {
"actor_critic_benchmark": "benchmark"
}
}
Commit: c4538fc9c6e6cd5f1fb91ba742d95225ca4ad4a1
Results summary:
data: ActorCritic_CartPole-v0_2018_02_04_013652
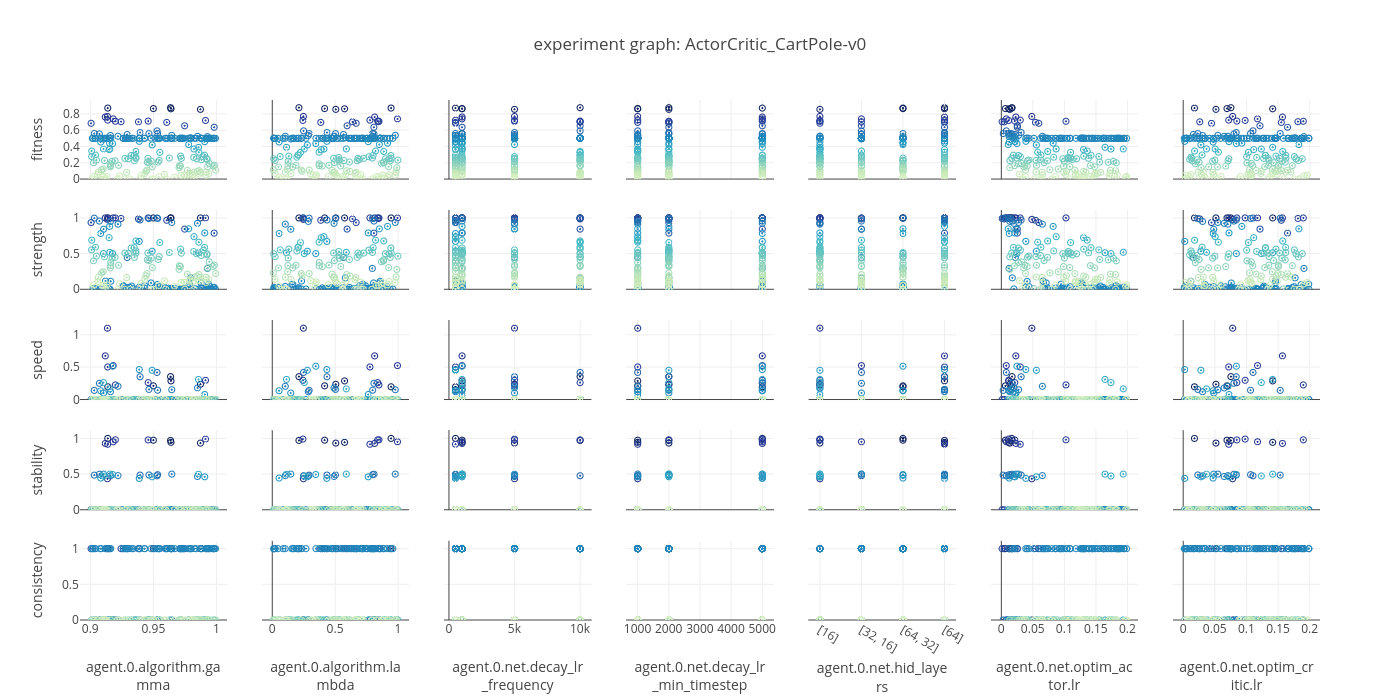
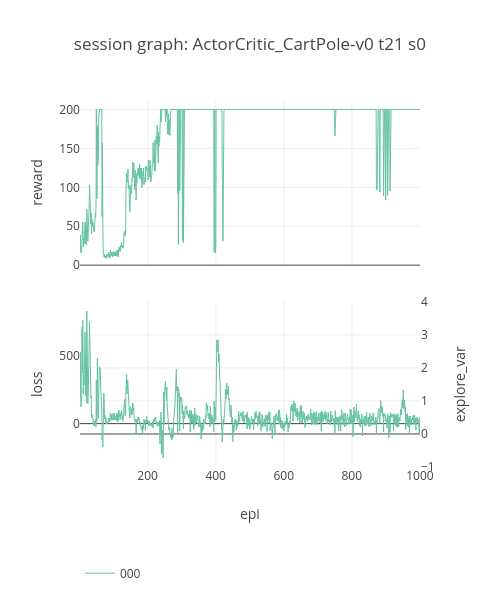
old AC specs, to clean out later
{
"actor_critic_benchmark": {
"agent": [{
"name": "ActorCritic",
"algorithm": {
"name": "ActorCritic",
"action_policy": "default",
"gamma": 0.99,
"add_entropy": false,
"entropy_coef": 0.01,
"continuous_action_clip": 2.0,
"training_frequency": 1,
"training_iters_per_batch": 8,
"use_gae": false,
"lam": 1.0,
"num_step_returns": 100,
"policy_loss_coef": 1.0,
"val_loss_coef": 1.0
},
"memory": {
"name": "OnPolicyReplay"
},
"net": {
"type": "MLPshared",
"hid_layers": [64],
"hid_layers_activation": "relu",
"use_same_optim": true,
"actor_optim_spec": {
"name": "Adam",
"lr": 0.01
},
"critic_optim_spec": {
"name": "Adam",
"lr": 0.01
},
"lr_decay": "no_decay",
"lr_decay_frequency": 1000,
"lr_decay_min_timestep": 2000
}
}],
"env": [{
"name": "CartPole-v0",
"max_timestep": null,
"max_episode": 1000
}],
"body": {
"product": "outer",
"num": 1
},
"meta": {
"max_session": 4,
"max_trial": null,
"search": "EvolutionarySearch",
"max_generation": 4
},
"search": {
"agent": [{
"algorithm": {
"gamma__uniform": [0.9, 0.9999]
},
"net": {
"hid_layers__choice": [
[16],
[64],
[32, 16],
[64, 32]
],
"actor_optim_spec": {
"lr__uniform": [0.001, 0.2]
},
"critic_optim_spec": {
"lr__uniform": [0.001, 0.2]
}
}
}]
}
},
"actor_critic_cartpole_recurrent": {
"agent": [{
"name": "ActorCritic",
"algorithm": {
"name": "ActorCritic",
"action_policy": "default",
"gamma": 0.99,
"add_entropy": false,
"entropy_coef": 0.01,
"continuous_action_clip": 2.0,
"training_frequency": 1,
"training_iters_per_batch": 4,
"use_gae": true,
"lam": 1.0,
"num_step_returns": 10,
"policy_loss_coef": 1.0,
"val_loss_coef": 1.0
},
"memory": {
"name": "OnPolicyNStepBatchReplay"
},
"net": {
"type": "Recurrentseparate",
"hid_layers": [16],
"hid_layers_activation": "relu",
"seq_len": 4,
"use_same_optim": false,
"actor_optim_spec": {
"name": "Adam",
"lr": 0.01
},
"critic_optim_spec": {
"name": "Adam",
"lr": 0.01
},
"lr_decay": "rate_decay",
"lr_decay_frequency": 600,
"lr_decay_min_timestep": 1000
}
}],
"env": [{
"name": "CartPole-v0",
"max_timestep": null,
"max_episode": 150
}],
"body": {
"product": "outer",
"num": 1
},
"meta": {
"max_session": 1,
"max_trial": 1,
"search": "RandomSearch"
}
},
"actor_critic_conv_breakout": {
"agent": [{
"name": "ActorCritic",
"algorithm": {
"name": "ActorCritic",
"action_policy": "default",
"gamma": 0.99,
"add_entropy": false,
"entropy_coef": 0.01,
"continuous_action_clip": 2.0,
"training_frequency": 1,
"training_iters_per_batch": 4,
"use_gae": true,
"lam": 1.0,
"num_step_returns": 10,
"policy_loss_coef": 1.0,
"val_loss_coef": 1.0
},
"memory": {
"name": "OnPolicyReplay"
},
"net": {
"type": "Convseparate",
"hid_layers": [
[
[3, 16, [5, 5], 2, 0, [1, 1]],
[16, 32, [5, 5], 2, 0, [2, 2]],
[32, 32, [5, 5], 2, 0, [2, 2]]
],
[128, 64]
],
"hid_layers_activation": "relu",
"use_same_optim": false,
"actor_optim_spec": {
"name": "Adam",
"lr": 0.01
},
"critic_optim_spec": {
"name": "Adam",
"lr": 0.01
},
"lr_decay": "rate_decay",
"lr_decay_frequency": 600,
"lr_decay_min_timestep": 1000
}
}],
"env": [{
"name": "Breakout-v0",
"max_timestep": null,
"max_episode": 1
}],
"body": {
"product": "outer",
"num": 1
},
"meta": {
"max_session": 1,
"max_trial": 1,
"search": "RandomSearch"
}
},
"actor_critic_cartpole": {
"agent": [{
"name": "ActorCritic",
"algorithm": {
"name": "ActorCritic",
"action_policy": "default",
"gamma": 0.91,
"add_entropy": true,
"entropy_coef": 0.01,
"continuous_action_clip": 2.0,
"training_frequency": 1,
"training_iters_per_batch": 4,
"use_gae": true,
"lam": 0.74,
"num_step_returns": 10,
"policy_loss_coef": 1.0,
"val_loss_coef": 1.0
},
"memory": {
"name": "OnPolicyReplay"
},
"net": {
"type": "MLPseparate",
"hid_layers": [
16
],
"hid_layers_activation": "relu",
"use_same_optim": false,
"actor_optim_spec": {
"name": "Adam",
"lr": 0.02
},
"critic_optim_spec": {
"name": "Adam",
"lr": 0.02
},
"lr_decay": "rate_decay",
"lr_decay_frequency": 1000,
"lr_decay_min_timestep": 2000
}
}],
"env": [{
"name": "CartPole-v0",
"max_timestep": null,
"max_episode": 200
}],
"body": {
"product": "outer",
"num": 1
},
"meta": {
"max_session": 4,
"max_trial": null,
"search": "EvolutionarySearch",
"max_generation": 5
},
"search": {
"agent": [{
"algorithm": {
"gamma__uniform": [0.8, 0.999]
},
"net": {
"hid_layers__choice": [
[16],
[32],
[16, 8],
[32, 16]
],
"actor_optim_spec": {
"lr__uniform": [0.002, 0.02]
},
"critic_optim_spec": {
"lr__uniform": [0.002, 0.02]
}
}
}]
}
},
"actor_critic_cartpole_coarse_search": {
"agent": [{
"name": "ActorCritic",
"algorithm": {
"name": "ActorCritic",
"action_policy": "default",
"gamma": 0.99,
"add_entropy": false,
"entropy_coef": 0.01,
"continuous_action_clip": 2.0,
"training_frequency": 1,
"training_iters_per_batch": 4,
"use_gae": true,
"lam": 1.0,
"num_step_returns": 10,
"policy_loss_coef": 1.0,
"val_loss_coef": 1.0
},
"memory": {
"name": "OnPolicyReplay"
},
"net": {
"type": "MLPseparate",
"hid_layers": [64],
"hid_layers_activation": "relu",
"use_same_optim": false,
"actor_optim_spec": {
"name": "Adam",
"lr": 0.01
},
"critic_optim_spec": {
"name": "Adam",
"lr": 0.01
},
"lr_decay": "rate_decay",
"lr_decay_frequency": 600,
"lr_decay_min_timestep": 1000
}
}],
"env": [{
"name": "CartPole-v0",
"max_timestep": null,
"max_episode": 1000
}],
"body": {
"product": "outer",
"num": 1
},
"meta": {
"max_session": 4,
"max_trial": 100,
"search": "RandomSearch"
},
"search": {
"agent": [{
"algorithm": {
"gamma__uniform": [0.9, 0.9999],
"training_iters_per_batch__choice": [1, 2, 3, 4, 5, 6, 8, 10],
"add_entropy__choice": [true, false]
},
"net": {
"type__choice": ["MLPshared", "MLPseparate"],
"hid_layers__choice": [
[16],
[32],
[64]
],
"hid_layers_activation__choice": ["relu", "sigmoid"],
"actor_optim_spec": {
"lr__uniform": [0.001, 0.2]
}
}
}]
}
},
"actor_critic_gridworld_coarse_search": {
"agent": [{
"name": "ActorCritic",
"algorithm": {
"name": "ActorCritic",
"action_policy": "default",
"gamma": 0.99,
"add_entropy": false,
"entropy_coef": 0.01,
"continuous_action_clip": 2.0,
"training_frequency": 1,
"training_iters_per_batch": 8,
"use_gae": true,
"lam": 1.0,
"num_step_returns": 100,
"policy_loss_coef": 1.0,
"val_loss_coef": 1.0
},
"memory": {
"name": "OnPolicyReplay"
},
"net": {
"type": "MLPshared",
"hid_layers": [64],
"hid_layers_activation": "relu",
"use_same_optim": true,
"actor_optim_spec": {
"name": "Adam",
"lr": 0.01
},
"critic_optim_spec": {
"name": "Adam",
"lr": 0.01
},
"lr_decay": "no_decay",
"lr_decay_frequency": 1000,
"lr_decay_min_timestep": 2000
}
}],
"env": [{
"name": "gridworld",
"max_timestep": 100,
"max_episode": 1000
}],
"body": {
"product": "outer",
"num": 1
},
"meta": {
"max_session": 4,
"max_trial": 100,
"search": "RandomSearch"
},
"search": {
"agent": [{
"algorithm": {
"gamma__uniform": [0.9, 0.9999],
"training_iters_per_batch__choice": [1, 2, 3, 4, 5, 6, 8, 10],
"add_entropy__choice": [true, false]
},
"net": {
"type__choice": ["MLPshared", "MLPseparate"],
"hid_layers__choice": [
[64],
[128],
[64, 32],
[128, 64]
],
"hid_layers_activation__choice": ["relu", "sigmoid"],
"actor_optim_spec": {
"lr__uniform": [0.001, 0.2]
}
}
}]
}
},
"actor_critic_2dball_coarse_search": {
"agent": [{
"name": "ActorCritic",
"algorithm": {
"name": "ActorCritic",
"action_policy": "default",
"gamma": 0.99,
"add_entropy": false,
"entropy_coef": 0.01,
"continuous_action_clip": 2.0,
"training_frequency": 1,
"training_iters_per_batch": 8,
"use_gae": true,
"lam": 1.0,
"num_step_returns": 100,
"policy_loss_coef": 1.0,
"val_loss_coef": 1.0
},
"memory": {
"name": "OnPolicyReplay"
},
"net": {
"type": "MLPshared",
"hid_layers": [64],
"hid_layers_activation": "relu",
"use_same_optim": true,
"actor_optim_spec": {
"name": "Adam",
"lr": 0.01
},
"critic_optim_spec": {
"name": "Adam",
"lr": 0.01
},
"lr_decay": "no_decay",
"lr_decay_frequency": 1000,
"lr_decay_min_timestep": 2000
}
}],
"env": [{
"name": "2dball",
"max_timestep": 200,
"max_episode": 1000
}],
"body": {
"product": "outer",
"num": 1
},
"meta": {
"max_session": 4,
"max_trial": 100,
"search": "RandomSearch"
},
"search": {
"agent": [{
"algorithm": {
"gamma__uniform": [0.9, 0.9999],
"training_iters_per_batch__choice": [1, 2, 3, 4, 5, 6, 8, 10],
"add_entropy__choice": [true, false]
},
"net": {
"type__choice": ["MLPshared", "MLPseparate"],
"hid_layers__choice": [
[16],
[32],
[64]
],
"hid_layers_activation__choice": ["relu", "sigmoid"],
"actor_optim_spec": {
"lr__uniform": [0.001, 0.2]
}
}
}]
}
},
"actor_critic_pendulum_coarse_search": {
"agent": [{
"name": "ActorCritic",
"algorithm": {
"name": "ActorCritic",
"action_policy": "default",
"gamma": 0.99,
"add_entropy": false,
"entropy_coef": 0.01,
"continuous_action_clip": 2.0,
"training_frequency": 1,
"training_iters_per_batch": 8,
"use_gae": true,
"lam": 1.0,
"num_step_returns": 100,
"policy_loss_coef": 1.0,
"val_loss_coef": 1.0
},
"memory": {
"name": "OnPolicyReplay"
},
"net": {
"type": "MLPshared",
"hid_layers": [64],
"hid_layers_activation": "relu",
"use_same_optim": true,
"actor_optim_spec": {
"name": "Adam",
"lr": 0.01
},
"critic_optim_spec": {
"name": "Adam",
"lr": 0.01
},
"lr_decay": "no_decay",
"lr_decay_frequency": 1000,
"lr_decay_min_timestep": 2000
}
}],
"env": [{
"name": "Pendulum-v0",
"max_timestep": null,
"max_episode": 1000
}],
"body": {
"product": "outer",
"num": 1
},
"meta": {
"max_session": 4,
"max_trial": 100,
"search": "RandomSearch"
},
"search": {
"agent": [{
"algorithm": {
"gamma__uniform": [0.9, 0.9999],
"training_iters_per_batch__choice": [1, 2, 3, 4, 5, 6, 8, 10],
"add_entropy__choice": [true, false]
},
"net": {
"type__choice": ["MLPshared", "MLPseparate"],
"hid_layers__choice": [
[64],
[128],
[256],
[64, 32],
[128, 64]
],
"hid_layers_activation__choice": ["relu", "sigmoid"],
"actor_optim_spec": {
"lr__uniform": [0.001, 0.2]
}
}
}]
}
},
"actor_critic_lunarlander_coarse_search": {
"agent": [{
"name": "ActorCritic",
"algorithm": {
"name": "ActorCritic",
"action_policy": "default",
"gamma": 0.99,
"add_entropy": false,
"entropy_coef": 0.01,
"continuous_action_clip": 2.0,
"training_frequency": 1,
"training_iters_per_batch": 8,
"use_gae": true,
"lam": 1.0,
"num_step_returns": 100,
"policy_loss_coef": 1.0,
"val_loss_coef": 1.0
},
"memory": {
"name": "OnPolicyReplay"
},
"net": {
"type": "MLPshared",
"hid_layers": [64],
"hid_layers_activation": "relu",
"use_same_optim": true,
"actor_optim_spec": {
"name": "Adam",
"lr": 0.01
},
"critic_optim_spec": {
"name": "Adam",
"lr": 0.01
},
"lr_decay": "no_decay",
"lr_decay_frequency": 1000,
"lr_decay_min_timestep": 2000
}
}],
"env": [{
"name": "LunarLander-v2",
"max_timestep": null,
"max_episode": 1000
}],
"body": {
"product": "outer",
"num": 1
},
"meta": {
"max_session": 4,
"max_trial": 100,
"search": "RandomSearch"
},
"search": {
"agent": [{
"algorithm": {
"gamma__uniform": [0.9, 0.9999],
"training_iters_per_batch__choice": [1, 2, 3, 4, 5, 6, 8, 10],
"add_entropy__choice": [true, false]
},
"net": {
"type__choice": ["MLPshared", "MLPseparate"],
"hid_layers__choice": [
[128],
[256],
[512],
[128, 64],
[256, 128]
],
"hid_layers_activation__choice": ["relu", "sigmoid"],
"actor_optim_spec": {
"lr__uniform": [0.001, 0.2]
}
}
}]
}
}
}
and actor critic studies spec
{
"actor_critic_cartpole_lam": {
"agent": [{
"name": "ActorCritic",
"algorithm": {
"name": "ActorCritic",
"action_policy": "default",
"gamma": 0.91,
"add_entropy": true,
"entropy_coef": 0.01,
"continuous_action_clip": 2.0,
"training_frequency": 1,
"training_iters_per_batch": 4,
"use_gae": true,
"lam": 1.0,
"num_step_returns": 10,
"policy_loss_coef": 1.0,
"val_loss_coef": 1.0
},
"memory": {
"name": "OnPolicyReplay"
},
"net": {
"type": "MLPseparate",
"hid_layers": [16],
"hid_layers_activation": "relu",
"use_same_optim": false,
"actor_optim_spec": {
"name": "Adam",
"lr": 0.02
},
"critic_optim_spec": {
"name": "Adam",
"lr": 0.02
},
"lr_decay": "rate_decay",
"lr_decay_frequency": 1000,
"lr_decay_min_timestep": 2000
}
}],
"env": [{
"name": "CartPole-v0",
"max_timestep": null,
"max_episode": 500
}],
"body": {
"product": "outer",
"num": 1
},
"meta": {
"max_session": 5,
"max_trial": 75,
"search": "RandomSearch"
},
"search": {
"agent": [{
"algorithm": {
"lam__uniform": [0.0, 1.0]
}
}]
}
},
"actor_critic_cartpole_batch_epi": {
"agent": [{
"name": "ActorCritic",
"algorithm": {
"name": "ActorCritic",
"action_policy": "default",
"gamma": 0.91,
"add_entropy": true,
"entropy_coef": 0.01,
"continuous_action_clip": 2.0,
"training_frequency": 1,
"training_iters_per_batch": 4,
"use_gae": true,
"lam": 1.0,
"num_step_returns": 10,
"policy_loss_coef": 1.0,
"val_loss_coef": 1.0
},
"memory": {
"name": "OnPolicyReplay"
},
"net": {
"type": "MLPseparate",
"hid_layers": [16],
"hid_layers_activation": "relu",
"use_same_optim": false,
"actor_optim_spec": {
"name": "Adam",
"lr": 0.02
},
"critic_optim_spec": {
"name": "Adam",
"lr": 0.02
},
"lr_decay": "rate_decay",
"lr_decay_frequency": 1000,
"lr_decay_min_timestep": 2000
}
}],
"env": [{
"name": "CartPole-v0",
"max_timestep": null,
"max_episode": 500
}],
"body": {
"product": "outer",
"num": 1
},
"meta": {
"max_session": 5,
"max_trial": 75,
"search": "RandomSearch"
},
"search": {
"agent": [{
"memory": {
"name__choice": ["OnPolicyReplay", "OnPolicyBatchReplay"]
}
}]
}
},
"actor_critic_cartpole_entropy": {
"agent": [{
"name": "ActorCritic",
"algorithm": {
"name": "ActorCritic",
"action_policy": "default",
"gamma": 0.91,
"add_entropy": true,
"entropy_coef": 0.01,
"continuous_action_clip": 2.0,
"training_frequency": 1,
"training_iters_per_batch": 4,
"use_gae": true,
"lam": 1.0,
"num_step_returns": 10,
"policy_loss_coef": 1.0,
"val_loss_coef": 1.0
},
"memory": {
"name": "OnPolicyReplay"
},
"net": {
"type": "MLPseparate",
"hid_layers": [16],
"hid_layers_activation": "relu",
"use_same_optim": false,
"actor_optim_spec": {
"name": "Adam",
"lr": 0.02
},
"critic_optim_spec": {
"name": "Adam",
"lr": 0.02
},
"lr_decay": "rate_decay",
"lr_decay_frequency": 1000,
"lr_decay_min_timestep": 2000
}
}],
"env": [{
"name": "CartPole-v0",
"max_timestep": null,
"max_episode": 500
}],
"body": {
"product": "outer",
"num": 1
},
"meta": {
"max_session": 5,
"max_trial": 75,
"search": "RandomSearch"
},
"search": {
"agent": [{
"algorithm": {
"entropy_coef__uniform": [0.0, 1.0]
}
}]
}
},
"actor_critic_cartpole_shared_param_losses": {
"agent": [{
"name": "ActorCritic",
"algorithm": {
"name": "ActorCritic",
"action_policy": "default",
"gamma": 0.91,
"add_entropy": true,
"entropy_coef": 0.01,
"continuous_action_clip": 2.0,
"training_frequency": 1,
"training_iters_per_batch": 4,
"use_gae": true,
"lam": 1.0,
"num_step_returns": 10,
"policy_loss_coef": 1.0,
"val_loss_coef": 1.0
},
"memory": {
"name": "OnPolicyReplay"
},
"net": {
"type": "MLPshared",
"hid_layers": [16],
"hid_layers_activation": "relu",
"use_same_optim": false,
"actor_optim_spec": {
"name": "Adam",
"lr": 0.02
},
"critic_optim_spec": {
"name": "Adam",
"lr": 0.02
},
"lr_decay": "rate_decay",
"lr_decay_frequency": 1000,
"lr_decay_min_timestep": 2000
}
}],
"env": [{
"name": "CartPole-v0",
"max_timestep": null,
"max_episode": 500
}],
"body": {
"product": "outer",
"num": 1
},
"meta": {
"max_session": 5,
"max_trial": 75,
"search": "RandomSearch"
},
"search": {
"agent": [{
"algorithm": {
"val_loss_coef__uniform": [0.1, 2.0]
}
}]
}
},
"actor_critic_cartpole_critic_lr": {
"agent": [{
"name": "ActorCritic",
"algorithm": {
"name": "ActorCritic",
"action_policy": "default",
"gamma": 0.91,
"add_entropy": true,
"entropy_coef": 0.01,
"continuous_action_clip": 2.0,
"training_frequency": 1,
"training_iters_per_batch": 4,
"use_gae": true,
"lam": 1.0,
"num_step_returns": 10,
"policy_loss_coef": 1.0,
"val_loss_coef": 1.0
},
"memory": {
"name": "OnPolicyReplay"
},
"net": {
"type": "MLPseparate",
"hid_layers": [16],
"hid_layers_activation": "relu",
"use_same_optim": false,
"actor_optim_spec": {
"name": "Adam",
"lr": 0.02
},
"critic_optim_spec": {
"name": "Adam",
"lr": 0.02
},
"lr_decay": "rate_decay",
"lr_decay_frequency": 1000,
"lr_decay_min_timestep": 2000
}
}],
"env": [{
"name": "CartPole-v0",
"max_timestep": null,
"max_episode": 500
}],
"body": {
"product": "outer",
"num": 1
},
"meta": {
"max_session": 5,
"max_trial": 75,
"search": "RandomSearch"
},
"search": {
"agent": [{
"net": {
"critic_optim_spec": {
"lr__uniform": [0.005, 0.05]
}
}
}]
}
}
}